technika
XML jako tabulka
internet je plný různých příkladů, jak tabulkově orientovaná data dostat z XML do SQL databáze. já ale musel řešit jiný problém – jak dostat XML do tabulky tak, aby v ní nebyla jen data, ale celý XML soubor, pěkně řádek po řádku.
typické XML, které musím zpracovávat, vypadá nějak tako:
<?xxml version="1.0" encoding="UTF-8"?><VYDANI><IDENTIFIKACE><DOKUMENT KOD="XML-structure"/> <VERZE>700778</VERZE><FUNKCE KOD="Ukázka"/><DATUM>20110203</DATUM></IDENTIFIKACE><VYKAZ><INF O><SUBJEKT>001</SUBJEKT><ROZSAH>XS-44</ROZSAH><DATUM>20110131</DATUM></INFO></VYKAZ><DATA><R ADEK PORADI="1"><SLOUPEC PORADI="1">1101000001</SLOUPEC><SLOUPEC PORADI="3">CZ</SLOUPEC><SLO UPEC PORADI="4">1667064</SLOUPEC><SLOUPEC PORADI="5">08</SLOUPEC></RADEK><RADEK PORADI="2">< SLOUPEC PORADI="1">1101000002</SLOUPEC><SLOUPEC PORADI="3">CZ</SLOUPEC><SLOUPEC PORADI="4">1 667064</SLOUPEC><SLOUPEC PORADI="5">08</SLOUPEC></RADEK><RADEK PORADI="3"><SLOUPEC PORADI="1 ">1101000003</SLOUPEC><SLOUPEC PORADI="3">CZ</SLOUPEC><SLOUPEC PORADI="4">1667064</SLOUPEC>< SLOUPEC PORADI="5">08</SLOUPEC></RADEK><RADEK PORADI="4"><SLOUPEC PORADI="1">1101000004</SLO UPEC><SLOUPEC PORADI="3">CZ</SLOUPEC><SLOUPEC PORADI="4">1643064</SLOUPEC><SLOUPEC PORADI="5 ">08</SLOUPEC></RADEK><RADEK PORADI="5"><SLOUPEC PORADI="1">1101000005</SLOUPEC><SLOUPEC POR ADI="3">CZ</SLOUPEC><SLOUPEC PORADI="4">1466932</SLOUPEC><SLOUPEC PORADI="5">08</SLOUPEC></R ADEK><RADEK PORADI="6"><SLOUPEC PORADI="1">1101000006</SLOUPEC><SLOUPEC PORADI="3">CZ</SLOUP EC><SLOUPEC PORADI="4">1466932</SLOUPEC><SLOUPEC PORADI="5">08</SLOUPEC></RADEK><RADEK PORAD I="7"><SLOUPEC PORADI="1">1101000007</SLOUPEC><SLOUPEC PORADI="3">CZ</SLOUPEC><SLOUPEC PORAD I="4">1666800</SLOUPEC><SLOUPEC PORADI="5">08</SLOUPEC></RADEK><RADEK PORADI="8"><SLOUPEC PO RADI="1">1101000008</SLOUPEC><SLOUPEC PORADI="3">SK</SLOUPEC><SLOUPEC PORADI="4">2670004</SL OUPEC><SLOUPEC PORADI="5">08</SLOUPEC></RADEK></DATA></VYDANI>
není ani formátované, žádné konce řádků. zpracovat to samozřejmě jde, ale pro lidské bytosti je to trochu nečitelné. kromě zmíněného přesunu do tabulky je tedy nutné provést i nějaké to formátování. požadovaný výstup vypadá takto (je ho jen kousek):
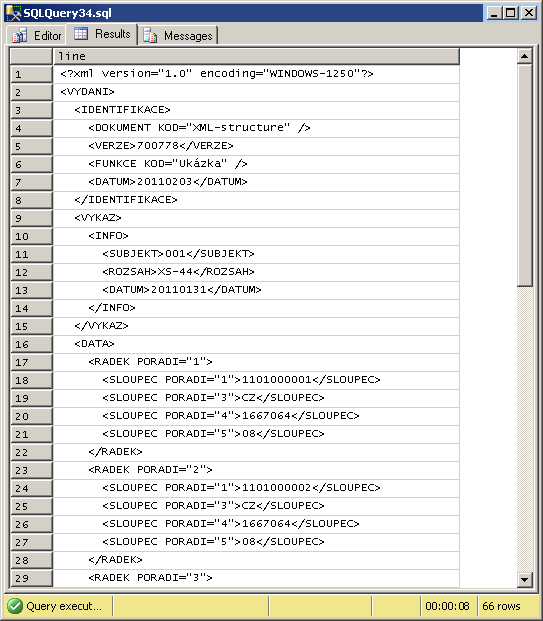
jak toho dosáhnout ? nejdříve jsem to zkusil přístupem klasickým – T-SQL proměnou typu XML jsem přetypoval na varchar(max). vzniklý text jsem rozsekal, přidal tabelátory a každý řádek nacpal do tabulky. celá akce byla ale neskutečně pomalá – XML o velikosti 1 MB to parsovalo 5 minut. holt T-SQL jazyk není zrovna ideální na zpracovávání textu, natož textu velkého. zkusil jsem tedy jinou metodu – rozebrat XML pomocí XQuery prostřednictvím funkcí datového typu. jelikož XQuery dotazy vrací jako typ XML, nejde celá akce udělat najednou. navíc, jak jsem po bližším zkoumání zjistil, implementace XQuery v podání Microsoftu je méně než polovičatá. celý kód jsem pojal jako fukci, ne uloženou proceduru – pro mojí potřebu se ukázala výhodnější, i když T-SQL user-defined funkce jsou také polovičaté až hrůza. zde je:
create function ftbl_XMLI(@xml as XML, @i as int)
returns @ret table(row int identity(1,1) unique, text varchar(1024))
as begin
-- vraci XML promennou jako tabulku, kde jednotlive radky odpovidaji radkum xml souboru
-- jeden radek souboru je omezen na 1024 znaku
-- pouzit varchar(max) by bylo univerzalnejsi, ale pomalejsi, na velkych xml souborech
-- je to znat
-- zalozime tabulku pro mezivysledek, jendu promenou pro drzeni aktualniho node a
-- druhou pro jeho textovou podobu
declare @buf table(text varchar(1024))
declare @node XML,
@ntxt varchar(1024)
-- pokud node obsahuje nejake komentare nebo instrukce, vyplivneme je na zacatek
set @ntxt = cast(@xml.query('processing-instruction()') as varchar(1024))
if @ntxt <> ''
insert into @ret (text)
values (@ntxt)
set @ntxt = cast(@xml.query('comment()') as varchar(1024))
if @ntxt <> ''
insert into @ret (text)
values (@ntxt)
-- vyselectujeme vsechny rootove nody
-- XQuery "*" nam vrati kazdy element, ktery najde v rootu, jako samostatny radek
declare cxml cursor local for
select node.col.query('.')
from @xml.nodes('*') as node(col)
open cxml
-- nacteme 1. element
fetch next from cxml into @node
while @@fetch_status = 0 begin
-- zavolanim sebe sama provedeme vypis dalsich elementu
-- XQuery "*[1]" vrati prvni element v rootu (je tam vzdy jen jeden)
-- "/*" pak vsechny jeho sub-elementy, ktere se tak predaji do rekurze
delete @buf
insert into @buf (text)
select text
from ftbl_XMLI(@node.query('*[1]/*'), @i + 1)
if @@rowcount = 0 begin
-- pokud se nic nevratilo, jsem na nejnizsim levelu a staci element
-- jen vypsat a opravit pouze drobny prohresek proti standardu
set @ntxt = rtrim(cast(@node as varchar(1024)))
if right(@ntxt, 2) = '/>'
set @ntxt = left(@ntxt, len(@ntxt) - 2) + ' />'
insert into @ret (text)
values (space(@i * 2) + @ntxt)
end else begin
-- pokud se nam neco vratilo, musime nejdrive vlozit tag zacatku elementu
-- se vsemi jeho attributy, pak vlozit obsah elementu a uzavrit to tagem konce
-- prijde mi zbytecne vytahovat attributy pomoci XQuery, pracovat s elementem
-- jako s textem bude jednoduzsi
-- v @node je ale ulozen cely element, ktery bude rozhodne delsi nez
-- zvolena delka 1 radku, takze ho trochu orezeme
-- provedme to tak, ze z elementu pomoci XQuery vymazeme vnitrek
-- (nepotrebujeme ho, uz je ulozen v tabulce @buf)
-- a pak jen rozparsujeme to, co se nam vrati jako text
set @node.modify('delete *[1]/*')
set @ntxt = cast(@node as varchar(1024))
insert into @ret (text)
values (space(@i * 2) + replace(@ntxt, '/>', '>'))
insert into @ret (text)
select text
from @buf
insert into @ret (text)
values (space(@i * 2) + '')
end
-- hura, jdeme na dalsi element
fetch next from cxml into @node
end
-- trochu po sobe uklidime a skoncime
close cxml
deallocate cxml
return
end
parametry funkce jsou dva – do prvního se vejde XML, které chceme zkonvertovat, druhý je používán při rekurzi. jeho hodnota se při každém vnoření zvedne o jednu. parametr je zároveň použit pro odsazení řádku. návratovou hodnotou funkce je klasická tabulka, která má definované dva sloupce. první sloupec se jmenuje row a je definován jako int. obsahuje čísla řádků a je tam proto, že se mi hodí. v jeho definici je mimo jiné použito klíčové slovo unique. jde o takovou malou fintu, s jeho pomocí lze držet paměťovou tabulku indexovanou. index lze pak využít například při třídění nebo rovnání, práce s tabulkou bude rychlejší. druhý sloupec se fádně jmenuje text, je typu varchar(1204) a je v něm jeden řádek převáděného XML. jako typ mohl být i varchar(max) nebo třeba nvarchar(max), ale mě 1 KB na řádek bohatě stačí.
na začátku funkce jsou založeny dvě proměnné. ta první, tabulková, je používána jako buffer na rozebraní jednoho XML elementu. ta druhá, typu XML, drží XML element, jak typ napovídá, v XML tvaru. po založení proměnných se funkce mrkne, jestli v XML elementu nejsou nějaké komentáře či jiná non-XML data a pokud ano, hned je uloží na výstup. následuje kurzor, který projede všechny elementy v nejvyšší úrovni přijatého XML, pěkně řádek po řádku. rozklad na řádky zajistí funkce nodes, která vyrobí sloupec col vr virtuální tabulce pojmenované node. pomocí funkce query je pak ze sloupce col vytažen XML element. kdyby byl sloupec typu XML, jak uvádí MS help, asi by to nebylo nutné, jenže on je typ XML tak nějak napůl. už si pomalu zvykám.
následující smyčka dělá hlavní práci. nejdříve jsou do bufferové tabulky načteny elementy, řazené pod elementem, který se zrovna projíždí. to je řešeno rekurzí – funkce prostě zavolá samu sebe, jen se pomocí XQuery posune na nižší úroveň v XML struktuře. pokud ani tato úroveň není nejnižší, rekurze se prohloubí. vnořování skončí v případě, že element už nemá žádné podelementy. technicky to zajistí smyčka, která neproběhne, protože kurzor, na který je navázána, nevrátí žádné řádky. po naplnění pomocné tabulky následuje rozhodování, zda se něco vrátilo nebo ne a na základě toho se provede uložení elementu do výstupní tabulky už v podobě textu.
téhle funkci trvá necelou minutu, než 1 MB velké XML rozparsuje. to je hodně mizerný výsledek a v žádném případě s ním nejsem spokojen. jenže v mé situaci je lepší pomalá funkčnost, než žádná a je to přecijen lepší, než verze s parsováním textu. nejde mi to do hlavy, protože parsovaní přes text je rozhodně méně náročné na prostředky, ale tak to prostě je. pro úplnost, kód textového parsování vypadá takto:
create function [dbo].[ftbl_XML](@xml xml)
returns @ret table(row int identity(1,1), text varchar(max))
as begin
-- vraci XML jako textovy vystup, radek po radku, odsazeny
-- jeho nevyhoda ale je, ze neni zrovna z nejrychlejsich
declare @rows varchar(max),
@row varchar(max),
@chari int,
@charx int,
@chart int = 0
-- zkonvertujeme xml na varchar a jedem na to
set @rows = convert(varchar(max), @xml)
set @chari = isnull(charindex('><', @rows, 0), 0)
while @chari <> 0 begin
--nacteni jednoho radku
set @row = left(@rows, @chari)
--posunuti na dalsi radek
set @rows = substring(@rows, @chari+1, 4294967295)
set @chari = isnull(charindex('><', @rows, 0), 0)
--odsazovani, v @chart je pocet odsazeni, v @row je co se tiskne
set @charx = 0
if @row like '%<[^?/]%[^?/]>%'
set @charx = @charx + 1
if @row like '%%'
set @charx = @charx - 1
if @charx < 0
set @chart = @chart + @charx
if @chart < 0
set @chart = 0
--vlozeni radku do tabulky
insert into @ret (text)
values (space(2*@chart)+@row)
-a jdeme na dalsi krok
if @charx > 0
set @chart = @chart + @charx
end
insert into @ret (text)
values (@rows)
return
end
funkce dělá totéž, co ta předchozí, jen to nebere rekurzí, ale postupným rozebráním XML v textové podobě. následující příklad ukazuje použití funkce (pro obě funkce je stejné). místo
declare @xml XML = 'tady je XML '
select text as line
from ftbl_XMLI(@xml, 0)
order by row
data
při své práci se setkávám s různými jazyky, dotazujícími se na data. je to hlavně T-SQL, který používám na MS SQL serveru 2008, XQuery také občas používané na stejném serveru a LINQ užívaný v .NOTu. seriál není žádnou výukou dotazovacích jazyků, jsou tu jen postřehy a přápadná řešení konkrétních situací.
- ODBC, Windows a 32/64bit - 23. 2. 2011
- INSERT EXEC - 4. 2. 2011
- XML jako tabulka - 3. 2. 2011
komentáře
jelikoz SQL a XML jsou veci, ktere me absolutne nezajimaji a nikdy zajimat nebudou, napisu ti jen, ze ta kombinace zelene a oranzove v titulku je dechberouci :)
Dobry den,
Chcem sa Vas opytat ci je mozne z XML mojho dodavatela vytvorit automaticku aktualizaciu poloziek v mojej databaze?
S pozdravom,
Bodnar
pro [2] - ono záleží, co máte za databázi, ale obecně to lze. pokud je to MS SQL SERVER, tak XML umí načíst přímo jako klasickou databázovou tabulu a tak s ní taky pracovat, tedy používat ji v SQL příkazech. pak stačí provést update dat z XML tabulky do té vaší.